
この記事では、交差検証(クロスバリデーション)について解説しています。
交差検証は、機械学習モデルの性能を正しくはかるために必須の知識です。
どんなに機械学習をまなんでも、性能が上がったのかどうか評価できなければ、意味がありません。
交差検証のやり方や、どのようなメリットがあるのか学んでいきましょう。
ホールドアウト法の問題点
交差検証は、ホールドアウト法の欠点をおぎなうために使われています。
そのため、まずはホールドアウト法とは何か、どこが問題なのかを見ていきます。
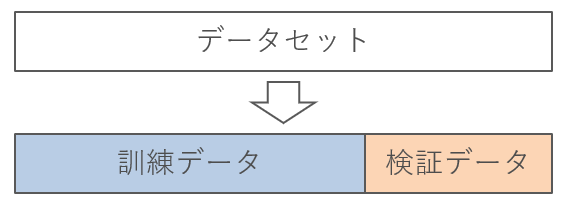
ホールドアウト法は、データセットを訓練データと検証データにわけます。
なぜデータをわけるかというと、機械学習のモデルをつくる目的は、未知のデータに適合させることだからです。
そのため、訓練データをつかって機械学習モデルを学習させて、検証データをつかって評価します。
こうすることで、過学習を防ぐことができ、未知のデータにも対応できるようになります。
過学習については別の記事で解説しています。

しかし、ホールドアウト法には欠点があります。
それは、検証データをまったく学習につかえないことです。
たとえば、訓練データと検証データにかたよりがあった場合、モデルの性能が落ちてしまいます。
また、データが少ない場合に、訓練データが少なくなってしまい、性能が十分に出せません。
そこで、ホールドアウト法の欠点をおぎなうために、交差検証が登場します。
k分割交差検証とは
交差検証にはいろいろな種類がありますが、ここではもっとも代表的な、k分割交差検証を紹介します。
k分割交差検証は、データをk個に分割して、1つを検証データにします。そして、残りのk-1個を訓練データとしてモデルの学習につかいます。
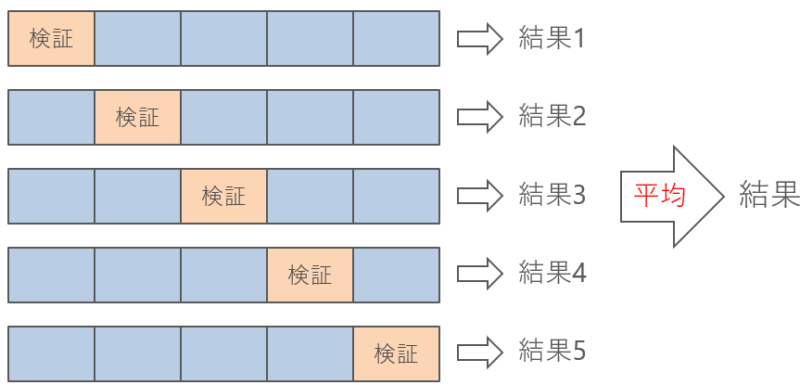
下の図は5分割交差検証です。
図を見ながら、ステップバイステップで解説します。
まず、2~5番目のデータを学習につかって、1番目のデータを検証につかいます。
この検証で得られた性能を、結果1として保存します。
次に、1、3、4、5番目のデータを学習につかって、2番目のデータを検証につかいます。
2番目のデータの検証結果を、結果2として保存します。
同じように繰り返していくと、結果が5個できます。
最終的に、5個の結果の平均を、機械学習モデルの性能とします。
つまり、5分割交差検証の手順は次のようにまとめられます。
- データを5分割にする
- 上で5分割にしたデータのうち、4つを訓練データ、1つを検証データとして評価する
- 検証データの位置を入れ替えていって、同じ操作を5回くりかえす
- 結果が5つ手に入るので、その平均を最終的なモデルの性能とする
ホールドアウト法との違いは、すべてのデータが訓練データ・検証データの両方につかわれていることです。
これによってモデルの平均的な性能を担保することができます。
さらに、データが少ない場合でも、全部のデータをk-1回は学習に使えることになるので、データのかたよりの悪影響を減らすことができます。
最終的には、k回学習をおこなった結果の平均を、最後の結果として使います。
時系列の交差検証とは
時系列のデータでは、交差検証するときに気を付けなければいけません。
なぜなら、普通にk分割交差検証をすると、未来の情報をつかって過去を予測することになるからです。
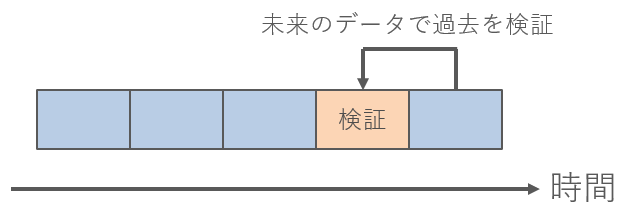
たとえば、5分割交差検証で、4番目のデータを検証にしたとすると、学習データに5番目のデータが含まれてしまいます。
検証データの時点では、未来の情報を知ることが不可能なのにもかかわらず、学習データに未来の情報を使ってしまっては、正しい予測ができません。
このように、未来のデータをつかって学習してしまうことを「リーク」とよびます。
時系列でリークを起こさないようにするには、過去のデータのみをつかって学習することです。
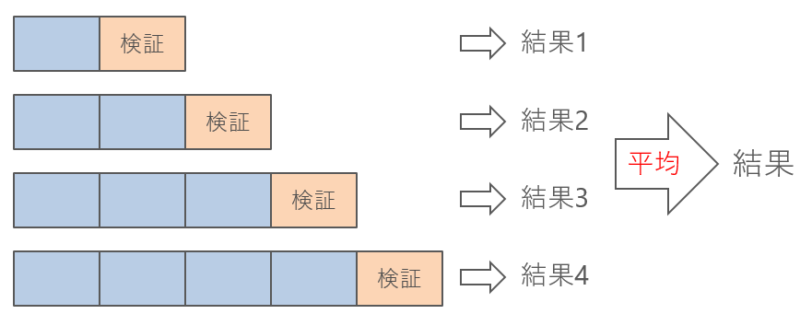
図のように、学習データを少しずつ伸ばしながら、検証期間をわけていくことが一般的です。
こうすることで、リークをさせずに学習させることができます。
まとめ
交差検証(クロスバリデーション)は、機械学習モデルの性能をはかるために必須です。
データを単純に、訓練データとテストデータにわけただけでは、検証データを有効活用できず、モデルの性能を十分にあげられません。
そのため、データをk個に分割して、k-1個を学習につかって、1個を評価につかいます。
評価につかうデータを1個ずつずらすと、モデルの平均的な性能をはかることができます。
最終的には、k個のモデルができるので、その平均を結果とします。
時系列データの場合には、未来のデータをつかうリークを避けるために、過去のデータだけをつかって学習することに注意してください。

