過学習(オーバーフィッティング)は、機械学習でよく直面する問題です。
機械学習でもっとも気を付けなければいけないポイントです。
本記事では、過学習の基本、原因、具体例、そして防止策について詳しく解説します。
過学習とは?
過学習とは、機械学習モデルが学習データに対して、必要以上に適合してしまう状況です。
たとえば、次のデータを考えてみましょう。

なんとなく直線的な関係がありそうに見えるので、グラフに直線を引いてみます。
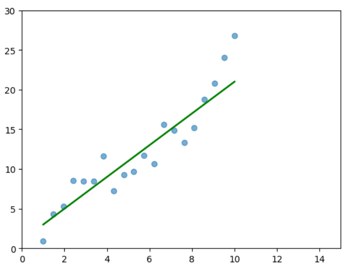
だいたい合っていそうに見えますが、ところどころのデータが直線から外れています。
もし、データにできるだけ合わせるような曲線を引いたら、どうなるでしょうか。
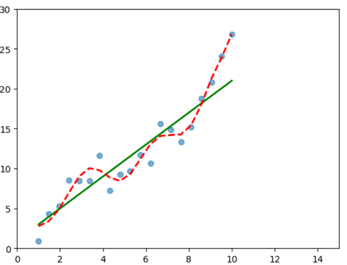
赤の破線はデータにできるだけ合うように、曲線のモデルを採用しました。
これだけ見ると、緑色の直線モデルよりも、赤色の曲線モデルのほうが良さそうに見えます。
しかし、モデルをつくり終わったあとに、新しいデータが取れました。
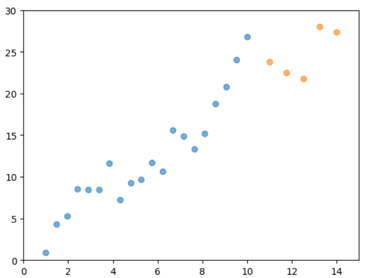
もともとのデータに加えて、右上にデータがふえています。
このデータにたいして、先ほどの直線モデルと曲線モデルを当てはめてみます。
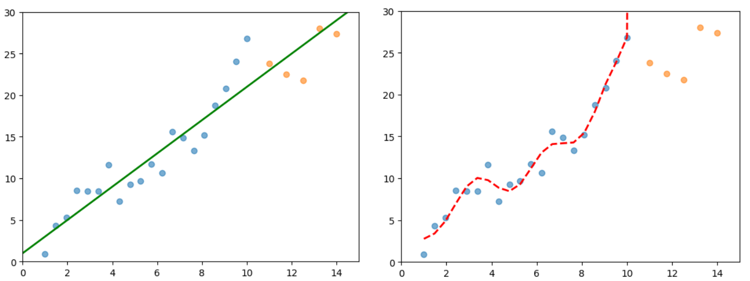
上図は同じデータにたいして、直線モデルと曲線モデルを当てはめた結果です。
明らかに、曲線モデルは未知のデータ(右上のオレンジ色のデータ)に適合できていません。
このように、学習データに合わせすぎて、未知のデータに適合できなくなることを「過学習」とよびます。
モデルをつくる理由は、未知のデータを予測することなので、曲線モデルは不適切です。
このように、モデルをつくるときは、単に学習データに合わせればいいのではなく、未知データに対しても正しく予測できることが重要です。
どうやったら過学習だとわかるのか
では、つくったモデルが過学習しているかどうか、どうやったら判定できるかを考えてみます。
過学習であるか判定するためのもっとも基本的な方法は、ホールドアウト法(Hold-out法)を使うことです。
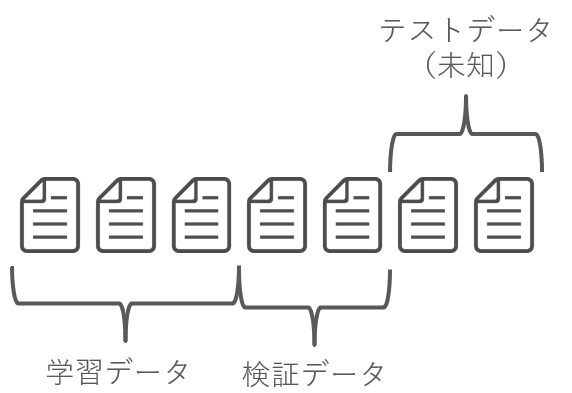
未知のデータはテストデータとよばれ、モデルをつくるときに知ることはできません。
そのため、事前にわかっているデータを「学習データ」と「検証データ」にわけます。
学習データをつかってモデルをつくり、検証データにも適合しているかどうか調べます。
そうすれば、未知のテストデータが取れたときも、過学習せずに適合させることができます。
学習データと検証データの比率は7:3や8:2にすることが多いです。
なぜなら、学習データが多くないと、そもそもモデルの性能が悪くなってしまうからです。
この方法は「ホールドアウト法」とよばれていて、データ分割のもっとも基本的な方法です。
実際には、ホールドアウト法ではなく、交差検証(クロスバリデーション)という方法が用いられることが多いです。
ホールドアウト法の問題点と、交差検証については、以下の記事でふれています。

過学習を防ぐための方法
過学習を防ぐ方法として、大きく2種類があります。
1つ目はデータ関連の対策、2つ目はモデル関連の対策です。
まず、データ関連の対策として、学習できるデータを増やせるなら、もっとも手っ取り早く過学習を防ぐことができます。
最近のAIモデルはかなり複雑な構造をもっていますが、データが非常に多いので過学習を起こさずに学習できています。
モデル関連の対策としては、L1/L2正則化、ドロップアウトがあります。
L1/L2正則化は、モデルの複雑さにたいしてペナルティをつけて、過学習を防ぐ技術です。
また、ドロップアウトは深層学習(Deep Learning)でつかわれる方法で、モデルの一部分だけを学習に使うことによって、過学習を回避します。
まとめ
本記事では、過学習の基本から、判定方法・防ぎ方まで解説しました。
過学習とは、学習データに適合しすぎて、未知のデータにたいして合わなくなってしまうことです。
モデルが複雑になると、過学習がおこりやすくなります。
過学習になっているかどうか判定するための最も基本的な方法は、ホールドアウト法といって、学習データと検証データに分割します。
検証データにも合うようなモデルをつくることで、過学習を回避することができます。
過学習を防ぐためには、データを増やしたり、モデルの複雑性にペナルティをつけることが有効です。

